LLM vs OCR Pipeline: Why the Answer Is Both
By Zakaria El Houda

A multimodal LLM can look at a scanned fund prospectus and extract the fee table in one API call. No template, no training data, no pipeline engineering. It reads the document the way a human would: visually, contextually, understanding that "Annual Fund Operating Expenses" is a section header and that 0.75% under "Management Fees" belongs to Class A shares.
So why would you build anything else?
Because the LLM will sometimes return 0.57% when the document says 0.75%. The number is plausible, formatted correctly, and sits in the right field. It passes every structural validation check. It's just wrong. And on financial documents where a fee discrepancy triggers a compliance flag, "usually right" is not a production-grade answer.
Traditional OCR pipelines have the opposite problem. They extract every character faithfully but have no idea what a fee table is. Textract returns the text "0.75%" with its exact page coordinates, but understanding that this value means "Management Fee for Class A" requires template engineering, layout rules, and field mapping that breaks every time a fund family changes its prospectus format.
The first post in this series introduced the hybrid pipeline pattern. The second post showed how we cross-check VLM-extracted table values against the PDF text layer. This post goes deeper: the economics, the cross-validation architecture, and when the hybrid pattern is worth building.
The Error That Benchmarks Don't Measure
Published benchmarks compare LLMs and OCR on field-level accuracy: did the model extract the right value for "Invoice Number"? On that metric, multimodal LLMs win. On clean PDFs with embedded text, current models achieve 96-98% field accuracy12.
Those numbers hide the failure mode that matters in production. Field-level accuracy treats all errors equally. A missing field is easy to catch. A plausible wrong value is not.
On a financial document, "Total Net Assets: $1,234,567" extracted as "$1,234,567" is correct. Extracted as "$1,234,576" is a transposition that no downstream validation catches unless you have an independent source of truth. And if the model returns "$1,234,567 thousand" when the original said "$1,234,567," that hallucinated unit qualifier changes the value by three orders of magnitude.
We built a fund intelligence platform that processes thousands of prospectuses, annual reports, and SAIs during peak filing season. Early in the project, we benchmarked multimodal LLMs against our traditional pipeline on 500 fund documents. The headline accuracy numbers favored the LLM by 8 points. When we audited the errors, the picture changed: 73% of the LLM's mistakes were plausible wrong values. Only 31% of the traditional pipeline's mistakes were. The rest were obvious formatting failures that existing validation caught.
Plausible wrong values are the expensive errors. They pass automated checks, enter the data warehouse, and surface weeks later when an analyst notices a fund's expense ratio doesn't match the prospectus. Tracking down a silent data quality issue across thousands of documents costs more than the extraction itself.
The same problem shows up in clinical document handoffs. When a patient transfers from a hospital to a long-term care facility, the receiving facility gets a discharge summary, a medication reconciliation list, and care plans, often as scanned PDFs or faxed pages from a different EHR system. An LLM reads "metoprolol 50mg BID" and understands it's a cardiac medication taken twice daily. But if it returns "metoprolol 500mg" because it hallucinated a zero, the error is clinically dangerous and structurally invisible: the format is correct, the drug name is correct, the unit is correct. Only the number is wrong. OCR would have extracted "50mg" faithfully but wouldn't know which medication it belongs to or that "BID" means twice daily.
The RIKER framework quantified hallucination at scale: 172 billion tokens across 35 models showed that it is systematic, not random, varying predictably by model architecture and context length3. On financial tables, we see digit transposition on roughly 2-3% of complex extractions. On medication lists, the risk profile is different: lower volume, but a single wrong digit can cause patient harm. Both domains need the same mitigation: cross-validate LLM-extracted values against OCR source text.
What Each Approach Actually Costs
Cost comparisons in vendor marketing use per-page pricing that obscures the real economics. A Textract DetectDocumentText call costs $0.0015 per page. A multimodal LLM call on the same page costs $0.01-0.05 depending on the model and token count. That's a 7-33x difference per page, but per-page cost is the wrong unit of comparison. The right unit is cost per correctly extracted data point.
| Approach | Cost/1K Pages | Field Accuracy | Cost per Correct Field (est.) |
|---|---|---|---|
| Textract DetectDocumentText | $1.50 | Text only, no fields | N/A |
| Textract AnalyzeDocument (Forms+Tables) | $65 | 78-87%4 | ~$0.007 |
| Azure Document Intelligence | $10 | 93%4 | ~$0.001 |
| Multimodal LLM (vision) | $8.80-50 | 90-98%12 | ~$0.001-0.005 |
| Fine-tuned LayoutLMv3 | ~$0.09 (self-hosted GPU)5 | 94% (on trained types) | ~$0.00001 |
Per-page costs from AWS6, Azure7, and Berkeley5 benchmarks. Field accuracy from Koncile1 and Businessware4 benchmarks.
Self-hosted models are three orders of magnitude cheaper than any cloud API once you have training data. A fine-tuned LayoutLMv3 on an A100 GPU processes 1,000 pages for roughly $0.09. The same pages through a multimodal LLM cost $8.80-50. At 10,000 documents per month, the difference is $0.90 vs $88-500.
But the cheapest-per-page option (Textract text extraction) gives you raw text with no field understanding. The most accurate option (fine-tuned model) requires weeks of annotation and training. No single service wins on cost, accuracy, and flexibility simultaneously, which is why routing documents to the cheapest adequate extraction method matters more than picking a single approach.
Cross-Validation: Making Two Wrong Things Right
The first post covered the hybrid pipeline's routing logic: classify, extract with the right tool, validate, review. The missing piece is how LLM extraction and OCR extraction check each other.
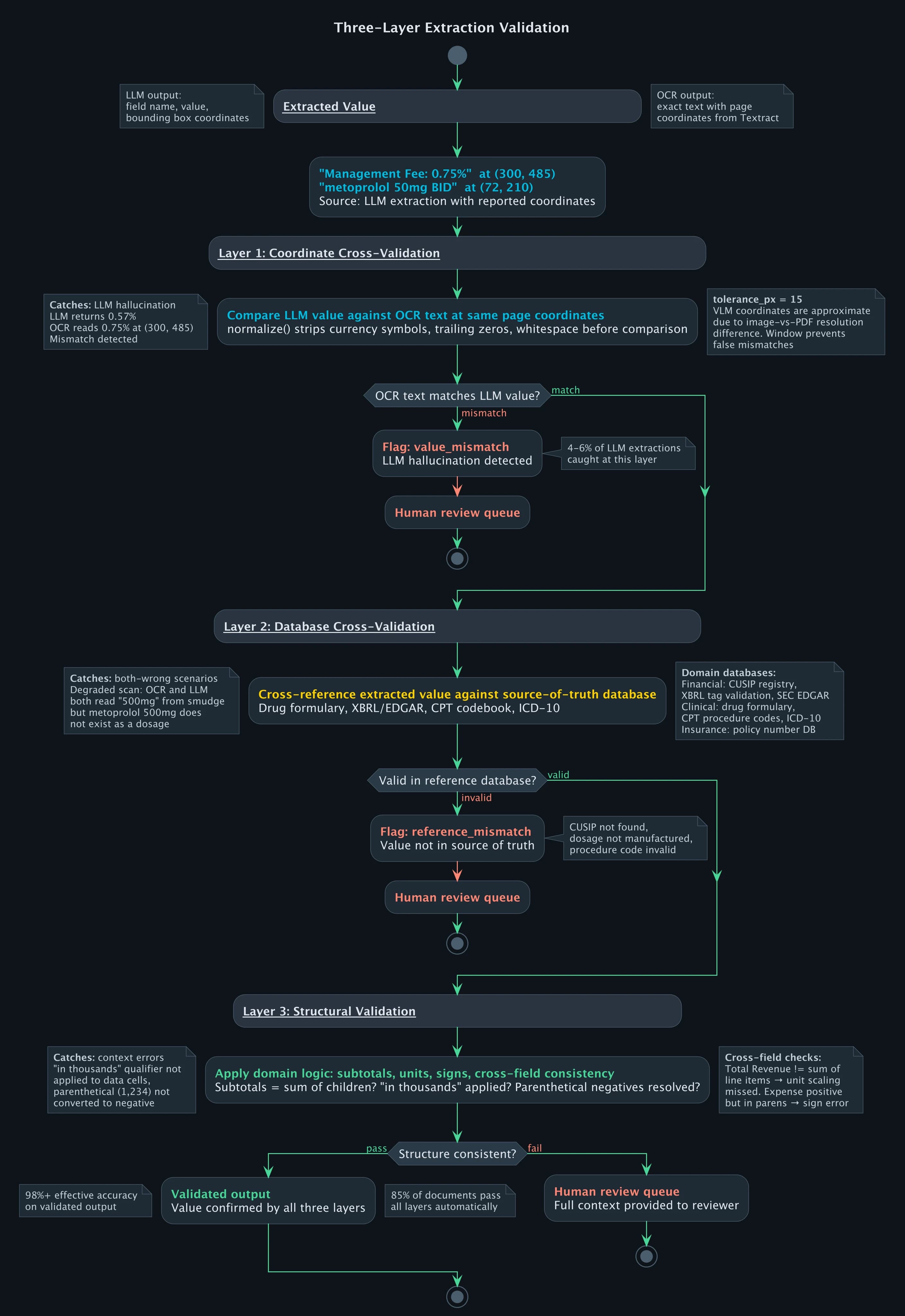
LLMs understand structure but fabricate values. OCR captures exact values but misses structure. Cross-validation exploits both strengths: the LLM identifies what a value means ("Management Fee for Class A"), and the OCR text layer confirms what the value actually is ("0.75%" at those page coordinates).
def cross_validate_extraction(llm_result, ocr_text_layer):
"""
Cross-check LLM-extracted values against OCR text at
the same page coordinates. Flag mismatches for review.
"""
validated = []
flagged = []
for field in llm_result["fields"]:
# find OCR text near the LLM's reported coordinates
ocr_match = ocr_text_layer.find_nearest(
field["bbox"], tolerance_px=15
)
if ocr_match and normalize(ocr_match.text) == normalize(field["value"]):
validated.append({**field, "source": "cross_validated"})
elif ocr_match:
flagged.append({
**field,
"ocr_value": ocr_match.text,
"llm_value": field["value"],
"reason": "value_mismatch",
})
else:
flagged.append({
**field,
"reason": "no_ocr_match_at_coordinates",
})
return validated, flagged
The tolerance_px parameter handles the fact that LLM-reported coordinates are approximate. A VLM processing a page image operates at a lower resolution than the PDF's native coordinate system, so the bounding box it returns for "0.75%" might be 10-15 pixels off from where Textract places the same text. The tolerance window accounts for this without being so wide that it matches adjacent cells.
Three edge cases need handling beyond the basic coordinate match.
OCR text present, LLM value reformatted. The LLM returns "1,234" but the OCR text reads "$1,234.00". Both are correct, just formatted differently. The normalize() function strips currency symbols, trailing zeros, and whitespace before comparison. Without normalization, roughly 15% of valid extractions get falsely flagged.
OCR text absent at coordinates. The LLM reports a value at coordinates where no OCR text exists. This happens on scanned documents where OCR missed a cell (low contrast, bleed-through) or when the LLM hallucinated a field that isn't on the page. Both cases go to human review, but the distinction matters for error tracking: one is an OCR quality problem, the other is an LLM reliability problem.
Multiple OCR candidates within tolerance. Dense financial tables can have two values within 15 pixels of each other. The pipeline picks the candidate with the highest spatial overlap with the LLM's bounding box, not just the nearest centroid. In practice this resolves correctly because LLM bounding boxes, while imprecise, are accurate enough to disambiguate adjacent cells.
Coordinate-level cross-validation catches cases where the LLM fabricated a value. It does not catch cases where both the LLM and OCR agree on a wrong value, which happens on degraded scans where the OCR misread the source. A third validation layer handles this: cross-referencing extracted values against source-of-truth databases.
Check the extracted dosage against a drug formulary: "metoprolol 500mg" is not a manufactured dosage, and the formulary flags it even if OCR and LLM both returned "500mg" from a smudged scan. The same principle applies to financial data. Validate extracted CUSIPs against the SEC's EDGAR company database, check that reported fund tickers resolve to real securities, cross-reference fee percentages against the fund's XBRL filings when available. Insurance claims have their own reference sets: CPT codebook for procedure codes, ICD-10 for diagnoses.
The pattern is the same across domains: every extracted value that has a canonical reference source gets checked against it. Coordinate cross-validation catches LLM hallucination. Database cross-validation catches OCR misreads and both-wrong scenarios.
On our fund intelligence pipeline, these layers together catch 4-6% of extractions that would have passed confidence thresholds. Combined with the structural validation from the table extraction post (subtotal consistency, parenthetical negatives, unit propagation), the pipeline flags roughly 15% of documents for human review. The remaining 85% go through fully automatically at 98%+ effective accuracy.
The Routing Economics
The hybrid pipeline's cost advantage comes from routing, not from any single technology being cheap.
| Document Category | % of Volume | Extraction Method | Cost/1K Pages |
|---|---|---|---|
| Known layout, high volume | 55% | Fine-tuned model (GPU) | $0.09 |
| Known layout, with tables | 30% | Textract Tables + post-processing | $15 |
| Unknown layout, long tail | 15% | Multimodal LLM + cross-validation | $30-50 |
| Weighted average | 100% | Hybrid | ~$9-12 |
Compare this to sending everything through a single service:
| Single-Service Approach | Cost/1K Pages |
|---|---|
| All Textract Forms+Tables | $65 |
| All Azure Document Intelligence | $10 |
| All multimodal LLM | $8.80-50 |
| Hybrid routing | $9-12 |
The hybrid approach isn't the cheapest at any single tier. It's the cheapest overall because 55% of volume goes through the $0.09/1K path. The Berkeley benchmark5 measured template-based extraction at 520x faster and 3,700x cheaper than LLM-based extraction for standardized documents. A self-hosted model handling the high-volume known layouts subsidizes the expensive LLM calls for the long tail.
Accuracy follows the same pattern. A fine-tuned model at 94% F1 on known layouts is more accurate than an LLM on those same layouts, because the model was trained specifically on that document type. The LLM is more accurate on unknown layouts because it generalizes where the fine-tuned model hasn't learned. Each tier handles the documents it's best suited for.
The routing split varies by domain. Fund document processing skews toward high volume with known layouts (55% fine-tuned model), because the same fund families file similar documents year after year. Clinical document handoffs skew the other way: every hospital system generates discharge summaries in a different format, so a larger share goes through the LLM tier. The cost per page is higher, but the volume is lower and the accuracy requirement on medication data is non-negotiable.
Throughput reinforces the routing decision. In the Businessware benchmark, GPT-4o took 16.9 seconds per invoice page4. Textract took 2.9 seconds. A fine-tuned model on GPU takes under 100ms. At 50,000 pages per day during peak filing season, putting everything through LLMs requires parallelism infrastructure that costs more than the per-page price suggests: concurrent API rate limits, retry handling, timeout management, and reconciliation for non-deterministic outputs.
When to Skip the Hybrid Approach
Not every document processing system needs this architecture.
If your volume is under 1,000 pages per month, the engineering cost of building routing logic exceeds the savings. Use a multimodal LLM for everything and add a human review step.
If your documents are all the same format (one bank's statements, one regulator's forms), a fine-tuned model with no LLM layer is cheaper and more accurate. The LLM adds value only when layout variation exceeds what a single model can learn.
If you don't need numerical precision (sentiment analysis on contracts, topic classification on correspondence), the hallucination problem is less critical. An LLM extracting "the contract mentions a 5-year term" is fine even if the actual term is 4 years and 11 months. An LLM extracting "metoprolol 500mg" when the discharge summary says "50mg" is not.
The volume threshold depends on the cost of errors. For financial documents, the hybrid architecture pays for itself above roughly 5,000 pages per month, where routing complexity starts saving more than it costs. For clinical documents where a wrong dosage creates patient safety risk, the cross-validation layer is worth building even at lower volumes. The routing tiers may be simpler (fewer known templates), but the cross-check against OCR source text is non-negotiable.
Frequently Asked Questions
Can multimodal LLMs replace OCR for document processing?
For variable-layout documents at moderate volumes, multimodal LLMs can handle the full extraction. For high-volume processing, traditional OCR is 520x faster and up to 3,700x cheaper per page5. Most production systems use both: LLMs for semantic understanding and the long tail of document formats, OCR and fine-tuned models for high-volume known layouts.
How do you prevent LLM hallucination in document extraction?
Cross-validate every LLM-extracted value against the OCR text layer. The OCR extracts exact characters from the source document with no generative component. If the LLM returns a value that doesn't match the OCR text at the same page coordinates, the extraction gets flagged for review. Structural validation (subtotals matching, units propagated) catches errors that coordinate-level checks miss.
What is the real cost difference between LLM and OCR document processing?
Raw per-page costs range from $0.0015 (Textract text extraction) to $0.05 (multimodal LLM with vision). But per-page cost is misleading. Self-hosted fine-tuned models process 1,000 pages for $0.09 on GPU. The cost-per-correctly-extracted-field is the metric that matters, and it favors hybrid routing: cheap models for known layouts, LLMs for the long tail.
How accurate is AI document processing on financial documents?
On clean, single-layout documents, 95-98%. On complex financial tables with merged cells, hierarchical headers, and cross-page continuations, off-the-shelf services drop to 40-60%4. Fine-tuned models reach 94% field-level F1 on trained document types. Hybrid pipelines with cross-validation and human review on flagged documents achieve 98%+ effective accuracy.
What volume justifies building a hybrid document processing pipeline?
Above 5,000 pages per month with variable layouts and accuracy requirements above 95%. Below that threshold, the engineering cost of routing logic, model hosting, and cross-validation infrastructure exceeds the savings over a simpler LLM-based approach with human review.
References
Footnotes
Document AI
Part 3 of 4
- 1.Document Processing in Production: Why Every Platform Breaks at 60%
- 2.PDF Table Extraction: Why Structure Recognition Breaks
- 3.LLM vs OCR Pipeline: Why the Answer Is Both
- 4.SEC EDGAR and XBRL: Financial Document AI at Scale